AI FAQ – How Bitrise leverages AI technologies in its features and services
As AI technologies are getting more and more popular, we collected answers of the most frequent questions on how Bitrise is leveraging these technologies. In this article, you can find detailed information on how AI and LLM tools are supported across Bitrise features and services.
At a glanceClick to copy link
Artificial Intelligence (AI) and more specifically large language models (LLMs) are rapidly becoming essential tools across the tech industry. Bitrise is actively investing in these new technologies that can enhance our platform and deliver smarter, more efficient solutions to our customers.
Security and reliability are paramount at Bitrise. We are dedicated to ensuring that our products or features using AI, like all our technologies, are employed responsibly and adhere to the industry standards.
This document should help understand how Bitrise implements AI, how Customer Content (defined below) is categorized and how customers can make choices whether to use or not use the features where AI functions are implemented.
Below we collected the most frequent questions we have received on how Bitrise is using AI technologies. We will update this document as we receive additional questions from customers.
How is Customer data used with AI on Bitrise?Click to copy link
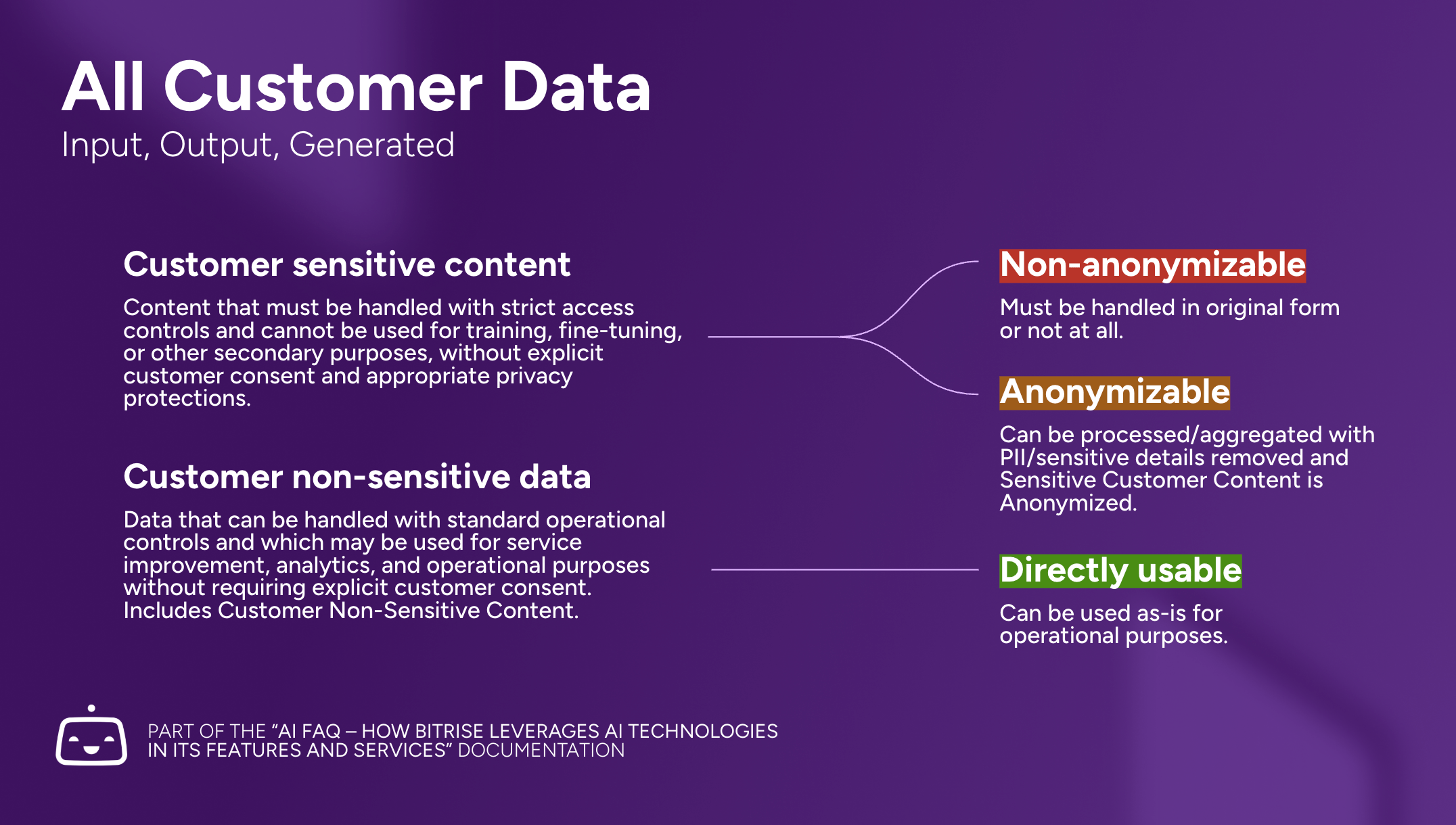
Bitrise classifies Customer data into the following Customer Content categories:
| Customer content category | Description |
|---|---|
| Customer Sensitive Content | Content that must be handled with strict access controls and cannot be used for training, fine-tuning, or other secondary purposes, without explicit customer consent and appropriate privacy protections. |
| Customer Non-Sensitive Data | Data that can be handled with standard operational controls and which may be used for service improvement, analytics, and operational purposes without requiring explicit customer consent. Includes Customer Non-Sensitive Content. |
Customer Sensitive Content and Non-sensitive Data shall be further classified as non-anonymizable, anonymizable, and directly useable, and may be processed as described below based on such classification:
| Type of Customer Content | Processing category |
|---|---|
| Non-Anonymizable (Customer Sensitive Content) | Non-Anonymized: Must be handled in original form or not at all. |
| Anonymizable (Customer Sensitive Content) | Anonymized: Can be processed/aggregated with PII/sensitive details removed and Sensitive Customer Content is Anonymized. |
| Directly Useable (Customer Non-Sensitive data) | Directly Used: Can be used as-is for operational purposes. |
Data classification detailsClick to copy link
-
Customer Sensitive Content:
This is Customer Content that customer inputs into the Bitrise Services that is confidential or proprietary to the customer, or that if otherwise is exposed or mishandled, could cause harm, competitive disadvantage, or a breach of the customer's confidentiality. This typically includes:
- Proprietary information (that is, source code, configuration secrets, business logic).
- Personal or identifying information that cannot be anonymized.
- Data subject to specific regulatory or contractual protection requirements.
-
Customer Non-Sensitive Data:
This is Customer data that provides information about the customer’s usage of the Bitrise Services or non-sensitive content input from the customer that, if exposed, would not cause business harm, competitive disadvantage, or breach of the customer’s confidentiality. This typically includes:
- Aggregated metrics and operational statistics.
- Non-identifying technical telemetry.
- Public information or data the customer has made publicly available.
- System performance data that doesn't reveal proprietary information.
The following table lists specific content types, their content classifications, and the type of processing they may be permitted (or in the case of Non-Anonymizable, which is not permitted):
| Data Type | Classification | Processing |
|---|---|---|
| Customer’s source code | Customer Sensitive Content | Non-Anonymizable |
| Environment variables | Customer Sensitive Content | Non-Anonymizable |
| Secrets for builds | Customer Sensitive Content | Non-Anonymizable |
| Auth secrets for third party integrations | Customer Sensitive Content | Non-Anonymizable |
| Artifacts | Customer Sensitive Content | Non-Anonymizable |
| Build cache blobs | Customer Sensitive Content | Non-Anonymizable |
| Connected Git accounts (for example, GitHub username, organization) | Customer Sensitive Content | Non-Anonymizable |
| Outgoing webhook URLs they set up | Customer Sensitive Content | Non-Anonymizable |
| Users and groups | Customer Sensitive Content | Non-Anonymizable |
| Connected SAML accounts | Customer Sensitive Content | Non-Anonymizable |
| App release metadata (Release Management) | Customer Sensitive Content | Non-Anonymizable |
| Generic files (required for builds) | Customer Sensitive Content | Non-Anonymizable |
| Code signing related files (test device data, UUIDs) | Customer Sensitive Content | Non-Anonymizable |
| Build Insights data (build failures over time, build duration over time, flaky tests, utilization, Git statistics and so on) | Customer Sensitive Content | Anonymizable |
| Pipeline configuration (bitrise.yml) | Customer Sensitive Content | Anonymizable |
| Test reports | Customer Sensitive Content | Anonymizable |
| Build logs | Customer Sensitive Content | Anonymizable |
| Access log (IP address) | Customer Sensitive Content | Anonymizable |
| List of third party tools customers use | Customer Sensitive Content | Anonymizable |
| Usage data, like: build count, build length, error rate, cache hit rate, bytes transferred, CLI and Step telemetry | Customer Non-Sensitive Data | Directly Useable |
| Document center search query | Customer Non-Sensitive Data | Directly Useable |
| Marketing analytics (Google Analytics, and so on) | Customer Non-Sensitive Data | Directly Useable |
| Infrastructure related data: VM load (CPU and memory), datacenter location, and so on. | Customer Non-Sensitive Data | Directly Useable |
| Website analytics | Customer Non-Sensitive Data | Directly Useable |
Does Bitrise retain Customer data for training?Click to copy link
Customer data is classified into several categories of customer content. The Customer Content is then handled as follows:
- Non-Anonymizable Customer Sensitive Content is never retained for training or fine-tuning purposes. For example, source code is never retained for any training/refining or any other purposes, whether or not such other purposes could lead Customer source code to leak into foundational or derivative models.
- Anonymized Customer Sensitive Content and Customer Non-Sensitive Data may be retained for use cases like fine tuning, predicting load, and to improve performance and reliability.
Where does Bitrise run its LLM inference?Click to copy link
Bitrise differentiates between the following Inference Locations (where the model is used and meets Customer data). Not all models are available at all Inference Locations.
| Inference Location | Deployment / Inference Location |
|---|---|
| "Local" | On-device, where the service is running – for example, on the same server where the build/test process is happening |
| "Bitrise-hosted GPU" | Inside Bitrise-managed VPC and servers |
| "Bitrise-controlled CSP account" | For example, AWS Bedrock, GCP Vertex AI |
| "Third-party API vendor" | For example, OpenAI, Anthropic |
Which large language models (LLMs) does Bitrise use?Click to copy link
Bitrise utilizes the following model families, with their Inference Location indicating where each model is used and interacts with Customer data.
| Model name / Provider | Deployment / Inference Location | Data RetentionThe Data Retention is set by the LLM service provider for regulatory/safety compliance. Bitrise does not retain data and works with LLM service providers to set Zero Data Retention wherever possible. by the service provider |
|---|---|---|
| Gemini models (proprietary models) | GCP Vertex AI | Zero Data Retention |
| OpenAI models (proprietary models) | OpenAI hosted API endpoints | Ephemeral <30 days |
| Anthropic models (proprietary models) | Anthropic hosted API endpoints | Zero Data Retention |
| Anthropic models (proprietary models) | AWS Bedrock | Zero Data Retention |
| Grok models | X.ai hosted API endpoints | Zero Data Retention |
How often does Bitrise update its AI models?Click to copy link
Bitrise is continuously working to enhance AI features by testing and updating models regularly as they become available.
These updates are designed to improve accuracy, security, and performance while respecting your data privacy and without interrupting your workflows. Models go through rigorous evaluations before they are elevated to production use.
Which Bitrise features use AI/LLMs?Click to copy link
| Feature | Type of Customer data involved | Allowed Inference Locations | Allowed Models |
|---|---|---|---|
| Code reviewer | - Parts of Customer’s source code (diff hunks, changed files, and so on) | all | all |
| Bitrise Coding Agent | - Customer’s source code - Environment variables - Secrets for builds | all | all |
| Compare invocations / analysis | - Usage data: build count, build length, error rate, cache hit rate, bytes transferred, etc. - Infrastructure related data: VM load (CPU and memory) and related telemetry, datacenter location - Environment variables - Parts of customer’s source code | all | all |
| AI Assistant | - Parts of Customer's build log (failed Step log chunks) - Build metadata like: Step title, stack name, machine type, Git branch name, commit messages. | all | all |
Who owns the intellectual property generated by LLMs?Click to copy link
Ownership follows the same data‑classification logic we apply throughout this FAQ: the more closely a piece of AI output can be traced back to your original, non‑anonymizable material, the more completely it belongs to you. Everything else remains ours.
| Category of input data that produced the AI output | Who owns the output? | Rationale |
|---|---|---|
| Non-Anonymizable Customer Sensitive Content (for example, your source code, build secrets, etc.) | Customer (you) | This output is effectively an extension of content you already own and that we commit never to retain or use for secondary purposes. |
| Anonymized Customer Sensitive Content (for example, anonymized build logs, failure statistics, etc.) | Bitrise | Once sensitive fields are stripped, the output no longer carries proprietary customer information. We may reuse it to improve the service. |
| Customer Non-Sensitive Data (for example, telemetry, publicly available metadata, search input string, etc.) | Bitrise | These inputs are either non-sensitive in nature, or generated by or already belong to Bitrise. |
What you can do with Bitrise‑owned outputClick to copy link
Bitrise-owned outputs that are made available to you as part of the Bitrise Services are available for you to use together with the Bitrise Services that you are otherwise licensed to use.
What Bitrise can do with customer‑owned outputClick to copy link
If the output is derived from your Non‑Anonymizable Sensitive Content, Bitrise keeps no rights beyond those needed to generate and display it back to you. We do not reuse or re‑train models on that output without your explicit permission and all intellectual property rights remain with you. For example, if a coding agent operated by Bitrise generates code changes based on your source code, you fully own the generated code.
Is it possible to disable AI features on Bitrise?Click to copy link
Yes. Customers may disable AI features at:
- Feature level
- Workspace level
Please contact our support team if you want to disable or enable any or all AI assisted features.
How does Bitrise approach using AI-capabilities in their services?Click to copy link
When implementing AI in features, Bitrise aims to abide by the following:
- AI suggestions are always recommendations, never irreversible actions.
- AI augments, but never replaces human judgment in decision making.
- AI decisions must be explainable in clear, non‑technical language where feasible.
- Critical flows (for example, deployment, billing, etc.) always require explicit human confirmation.
- Bitrise is committed to transparent incident investigation and timely corrective action through our internal policies.